728x90
목차
1.의사결정나무
- 데이터 살펴보기
- datetime을 계절로 바꾸기
2.의사 결정 나무(Decision Tree)모델
3.선형회귀vs의사 결정 나무
6.의사 결정 나무.ipynb

1.의사결정나무
🎈 실습 !!
🔻사용할 라이브러리들 추가하기
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt🔻 미리 준비해둔 데이터 가져오기
bike_df = pd.read_csv('/content/drive/MyDrive/7.머신러닝 딥러닝/실습데이터/bike.csv')🔻 bike_df 데이터 확인 해보기
bike_df.info()
데이터 살펴보기
datetime : 날짜
count : 대여 개수
holiday : 휴일
workingday : 근무일
temp : 기온
feels_like : 체감온도
temp_min : 최저온도
temp_max : 최고온도
pressure : 기압
humidity : 습도
wind_speed : 풍속
wind_deg : 풍향
rain_1h : 1시간당 강수량
snow_1h : 1시간당 강수량(눈)
clouds_all : 구름의 양
weather_main : 날씨
🔻 아웃라이어와 숫자로된 데이터들을 확인 하기
# 숫자로 되어있는 데이터 확인하기
bike_df.describe()
sns.displot(bike_df['count'])
# 이상치가 존재 하는지 확인
sns.boxplot(bike_df['count'])
# 온도에 따른 카운트
sns.scatterplot(x='feels_like', y= 'count', data=bike_df, alpha=0.3)
# 기압 기준
sns.scatterplot(x='pressure', y= 'count', data=bike_df, alpha=0.3)
# 바람
sns.scatterplot(x='wind_speed', y= 'count', data=bike_df, alpha=0.3)
# 풍향 (풍향과는 전혀 관계가 없는듯)
sns.scatterplot(x='wind_deg', y= 'count', data=bike_df, alpha=0.3)
🔻결측치 확인하기
# 결측치 확인하기
bike_df.isna().sum()# 결측치 퍼센티지로 보기
bike_df.isna().mean()
🗨 비, 눈 빼고는 결측치가 존재 하지 않는거 같다 ~

🗨 데이터가 지금 비또는눈이 오지 않은날 빼고는 결측치가 존재 하지 않는 아주 이상적인 데이터셋이다.
🔻 결측치 처리하기
# 결측치를 처리 해주기위해서
# 비 또는 눈이 오지 않은날은 0으로 채우기
bike_df = bike_df.fillna(0)🔻 결측치 처리후 확인하기

🔻datetime을 계절로 바꾸기
bike_df['datetime'] = pd.to_datetime(bike_df['datetime'])# 파생변수 빼오기
bike_df['year'] = bike_df['datetime'].dt.year
bike_df['month'] = bike_df['datetime'].dt.month
bike_df['hour'] = bike_df['datetime'].dt.hourbike_df.head()
👀date에 날짜형태로 담기
bike_df['date'] = bike_df['datetime'].dt.datebike_df.head()
👀 date 그래프로 그려보기
plt.figure(figsize=(14,4))
sns.lineplot(x='date', y='count', data=bike_df)
plt.xticks(rotation=45)
plt.show()
# 2019년도의 count의 평균 확인한다.
bike_df[bike_df['year']== 2019].groupby('month')['count'].mean()
# 2020년도 4월 데이터가 없음.
# 그냥 우리 예상은 20년4월에 코로나때문에 대여를 하지 않았을까..? 아니면 영업을 하지 않았을까?
bike_df[bike_df['year']== 2020].groupby('month')['count'].mean()
👀 covid기준으로 나누기 precovid, covid, postcovid
# covid기준으로
# 2020-04-01 이전: precovid
# 2021-04-01 이전: covid
# 이후 : postcovid
def covid(date):
if str(date) < '2020-04-01':
return 'precovid'
elif str(date) < '2021-04-01':
return 'covid'
else :
return 'postcovid'# bike_df['date'] 의 내용을 covid()함수에 넣어주기 위해서는
bike_df['date'].apply(covid) # 이런식으로 해주어야 한다.
bike_df['covid'] = bike_df['date'].apply(lambda date: 'precovid' if str(date) < '2020-04-01' else 'covid' if str(date) < '2021-04-01' else 'postcovid')bike_df.head()
🔻 계절 파생변수 만들기
# 파생변수 이름 : season
# 3월~5월 : spring
# 6월~8월 : summer
# 9월~11월: fall
# 12월~2월: winter
bike_df['season'] = bike_df['month'].apply(lambda x: 'winter' if x == 12 else 'fall' if x>=9 else 'summer' if x >= 6 else 'spring' if x >= 3 else 'winter')
🔻month를 기준으로 계절 이름 주기

2.의사 결정 나무(Decision Tree)모델
- 스무고개같은 스타일의 모델
- 데이터를 분석하여 그 사이에 존재하는 패턴을 예측 가능한 규칙들의 조합으로 나타내며, 그모양이 '나무'와 같다고 해서 의사 결정 나무라고 부름
- 분류(Classification)과 회귀(Regression)을 모두 가능하게 해줌
- 지니계수(Gini Index) : 0 에 가까울수록 클래스에 속한 불순도가 낮다. 불순도란:
- 엔트로피(Entropy) : 결정을 내릴만한 충분한 정보가 데이터에 없다고 보는 것.(0에 가까울수록 "결정을 내릴만한 충분한 정보가 있다"라고 본다)지니 계수와 반비례할 수 있다
- 오버피팅(과적합) : 훈련데이터에서는 정확하나 테스트데이터에서는 성과가 나쁜 현상을 말함. 훈련 데이터가 적거나 노이즈가 있을 때 또는 알고리즘 자체가 나쁠 때 발생. 의사 결정 나무에서는 나무의 가지가 너무 많거나 크기가 클 때 발생한다.
- 의사 결정 나무에서 오버피팅을 피하는 방법
사전 가지치기: 나무가 다 자라기 전에 알고리즘을 멈추는 방법
사후 가지치기: 의사 결정 나무를 끝까지 돌린 후 밑에서부터 가지를 쳐나가는 방법
from sklearn.tree import DecisionTreeRegressor
dt = DecisionTreeRegressor(random_state = 10)
#학습
dt.fit(X_train, y_train)
#시험
pred1 = dt.predict(X_test)
sns.scatterplot(x=y_test, y=pred1)
🔻오차구하기
# 오차 구하기
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, pred1, squared=False)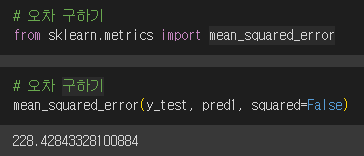
3.선형회귀vs의사 결정 나무
from sklearn.linear_model import LinearRegression
#객체 생성
lr = LinearRegression()
# 학습
lr.fit(X_train, y_train)
#예측 하기
pred2 = lr.predict(X_test)
# 그래프 그리기
sns.scatterplot(x=y_test, y=pred2)
mean_squared_error(y_test, pred2, squared=False)
# 의사 결정 나무 RMSE: 228.42843328100884
# 선형회귀 RMSE : 228.26128192004947
# 의사결정나무 - 선형회귀
228.42843328100884 - 228.26128192004947
# 현재 데이터를 사용했을때 선형회귀가 조금더 성능이 좋아보인다.

하이퍼 파라미터 적용하기
# 하이퍼 파라미터 적용
dt = DecisionTreeRegressor(random_state = 10, max_depth=50, min_samples_leaf=30)#학습
dt.fit(X_train, y_train)
pred3 = dt.predict(X_test)
mean_squared_error(y_test, pred3, squared=False)
from sklearn.tree import plot_tree
# 트리 그리기
plt.figure(figsize = (24,12))
plot_tree(dt, max_depth=5, fontsize=12)
plt.show
728x90
'개발 > 머신러닝-딥러닝' 카테고리의 다른 글
| 2023.06.12 ML(머신러닝)의 서포트 벡터 머신 (2) | 2023.06.14 |
|---|---|
| 2023.06.09 ML(머신러닝)의 로지스틱 회귀 (0) | 2023.06.13 |
| 2023.06.08 ML(머신러닝)의 선형회귀, 평기지표, log활용 (1) | 2023.06.12 |
| 2023.06.08 ML(머신러닝)의 Kaggle(캐글),타이타닉 데이터셋 (0) | 2023.06.09 |
| 2023.06.08 ML(머신러닝)의 Iris(아이리스) (0) | 2023.06.08 |




댓글