1.Rent 데이터셋 살펴보기
2.선형회귀(Linear Regression)
3.평가 지표 만들기
- 3-1.MSE(Mean Squared Error)
- 3-2.MAE(Mean Absolute Error)
- 3-3.RMSE(Root Mean Squared Error)
- 3-4.평가지표 적용하기
4.log활용하기
5.선형 회귀.ipynb

1.Rent 데이터셋 살펴보기
🎈실습 !!
- 미국 부동산 데이터셋을 이용한 실습을 진행 하겠습니다.
🔻 모듈과 데이터셋 불러오기
import numpy as np
import pandas as pd
import seaborn as sns
rent_df = pd.read_csv('/content/drive/MyDrive/7.머신러닝 딥러닝/실습데이터/rent.csv')
rent_df
🔻 데이터 확인하기
# 데이터의 정보 확인하기
rent_df.info()
데이터 칼럼 알아보기
- Posted On: 매물 등록 날짜
- BHK: 베드, 홀, 키친의 개수
- Rent: 렌트비
- Size: 집 크기
- Floor: 총 층수 중 몇층
- Area Type: 공용공간을 포함하는지, 집의 면적만 포함하는지
- Area Locality: 지역
- City: 도시
- Furnishing Status: 풀옵션 여부
- Tenant Preferred: 선호하는 가족형태
- Bathroom: 화장실 개수
- Point of Contact: 연락할 곳
🔻 우리가 사용할 데이터를 한번 확인 해봅시다.
# 막대 그래프 그리기
sns.displot(rent_df['Rent'])
👀🗨Rent의 값을 막대그래프로 그려 보니 뭔가 분포도가 이상한거 같습니다.
👀 'Rent'의 값을 한번 순서대로 뽑아 보겠습니다.
rent_df['Rent'].sort_values()
🗨 'Rent'의 값을 뽑아보니 1200~ 3500000인것을 확인 할수 있습니다.
👀 null값 확인하기
# sum()으로 null값 확인하기
rent_df.isna().sum()

# mean()으로 null값 확인해보기
rent_df.isna().mean()
🔻결측치가 있는 열 삭제 하기
# 결측치가 있는 열을 삭제 (df에 결과를 저장은 하지 않고 확인만)
# 1의 의미는 "na가 있는 열을 삭제 해라"
rent_df.dropna(1) # BHK, Size 열이 모두 삭제 , rent_df.drop('BHK', axis=1)
🔻결측치 처리 하기
# 결측치 처리 하기
# 1. 결측 데이터가 전체 데이터에 비해 양이 굉장히 적을 경우 삭제하는 것도 방법
# 2. 결측치에 데이터를 채울 경우 먼저 boxplot을 확인하는 것이 좋음
sns.boxplot(y=rent_df['Size'])
👀boxplot을 확인 후 mean 보다는 median을 사용하는게 좋다고 판단 됩니다.
# boxplot을 확인 후 mean 보다는 median을 사용하는게 좋다고 판단 됩니다.
rent_df.fillna(rent_df.median()).loc[na_index]
na_index = rent_df[rent_df['BHK'].isna()].index
na_index
rent_df['BHK'].fillna(rent_df['BHK'].median()).loc[na_index]
rent_df = rent_df.fillna(rent_df.median())
rent_df.isna().mean()
🔻 원 핫 인코딩 하기전 데이터를 한번 봅시다.
# 원 핫 인코딩을 해보자 ~
rent_df.info()
🔻 "Area Type"은 텍스트 형태를 숫자형태로 라벨인코딩 하겠습니다.
# Area Type은 텍스트 형태이기 때문에 모델에서 계산을 할 수 없다.
# 라벨 인코딩을 통해 숫자로 변경 해주어야 합니다.
rent_df['Area Type'].value_counts()
🔻중복값 제거후 확인
# 중복값 제거후 확인하는방법
rent_df['Area Type'].unique()
🔻 nunique()를 이용하여 유니크한 종류의 개수 구하기 !
# 유니크한 종류의 개수 구하기 !
rent_df['Area Type'].nunique()
🔻위에서 사용한 유니크한 종류 개수를 다른 칼럼들도 구해 보겠습니다.
Floor
Area Type
Area Locality
City
Furnishing Status
Tenant Preferred
Point of Contact
for i in ['Floor', 'Area Type', 'Area Locality', 'City', 'Furnishing Status', 'Tenant Preferred', 'Point of Contact']:
print(i, rent_df[i].nunique())
🔻불필요한 칼럼 삭제 하기
# 중요하지 않은 컬럼들 지우기 'Posted On', 'Floor', 'Area Locality', 'Tenant Preferred', 'Point of Contact'
rent_df.drop(['Posted On', 'Floor', 'Area Locality', 'Tenant Preferred', 'Point of Contact'], axis=1, inplace=True)
🔻 X에 독립변수 저장, y에 종속 변수 저장
X = rent_df.drop('Rent', axis =1) # 독립변수
y = rent_df['Rent'] # 종속변수🔻학습을 시키기 위해서 자료 준비
from sklearn.model_selection import train_test_split
#위에서 저장한 X(독립변수)와 y(종속변수)를 넣어 줍니다.
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=10)
#train을 shape로 갯수 확인
X_train.shape, y_train.shapeX_test.shape, y_test.shape
2.선형회귀(Linear Regression)
- 데이터를 통해 가장 잘 설명할 수 있는 직선으로 데이터를 분석 하는 방법을 '선형회귀'라 한다.
- 단순 선형 회귀 분석(단일 독립변수를 이용)
- 다중 선형 회귀 분석(다중 독립변수를 이용)
# LinearRegression 사용하기
from sklearn.linear_model import LinearRegression
# 객체 생성
lr = LinearRegression()
# 학습시키기
lr.fit(X_train, y_train)
🔻 pred에 예측 담기
pred = lr.predict(X_test)3.평가 지표 만들기
- 3-1.MSE(Mean Squared Error)
- 3-2.MAE(Mean Absolute Error)
- 3-3.RMSE(Root Mean Squared Error)
- 3-4.평가지표 적용하기
3-1.MSE(Mean Squared Error)
- 평균 제곱근 오차
- 예측값과 실제값의 차이에 대한 제곱에 대해 평균을 낸 값

🔻MSE(Mean Squared Error)
# MSE를 사용하기 위해 실제값 말고 우리가 그냥 값을 만들어 테스트
p = np.array([3,4,5]) # 예측값
act = np.array([1,2,3]) # 실제값
def my_mse(pred, actual):
return ((pred - actual) **2 ).mean()🔻 위에서 만든 my_mse함수 사용하기
# 숫자의 의미는 없다
# 선이 여러개 그어졌을때 서로의 선의 비교대상으로만 사용하면 된다.
my_mse(p, act)
🗨결과값으로 나온 숫자는 의미 없다.
3-2.MAE(Mean Absolute Error)
- 예측값과 실제값의 차이에 대한 절대값에 대해 평균을 낸 값
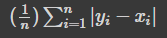
# MAE함수 만들기
def my_mae(pred, actual):
return np.abs(pred - actual).mean()
#함수 사용
my_mae(p,act)
3-3.RMSE(Root Mean Squared Error)
- 예측값과 실제값의 차이에 대한 제곱에 대해 평균을 낸 후 루트를 씌운 값

🔻 numpy를 이용하여 제곱근후 RMSE만들기
# np.sqrt 제곱근
def my_rmse(pred, actual):
return np.sqrt(my_mse(pred, actual))
# my_rmse함수사용
my_rmse(p,act)

🔻 라이브러리를 사용하여 모두 출력 해보기
# MAE, MSE 라이브러리 사용
from sklearn.metrics import mean_absolute_error, mean_squared_error
# MAE
mean_absolute_error(p,act)
# MSE
mean_squared_error(p, act)
#RMSE
mean_squared_error(p, act, squared=False)
3-4.평가지표 적용하기
🔻적용하기
# 우리가 선형회귀에서 구한 값을 적용해보자
mean_squared_error(y_test, pred)
# MAE
mean_absolute_error(y_test, pred)
🔻이상치 제거
# 이상치가 존재 하기때문에 오차율이 높게 나타는거 같아서
# 1837은 위에서 3500000 값을 가진 이상치
X_train.drop(1837, inplace=True)
y_train.drop(1837, inplace=True)
# 이상치 삭제후 다시 학습시키기
lr.fit(X_train, y_train)🔻예측하기
# 예측선 그리기# 예측을 합니다.
pred = lr.predict(X_test)🔻오차율 확인해보기
mean_squared_error(y_test, pred, squared=False)# index 1837 지우기 전 : 41438.9403701652
# index 1837 지우기 후 : 41377.57030234839
# 이상치를 하나 지웠다고 오차가 61.37006781680975줄었다
41438.9403701652-41377.57030234839
4.log활용하기
- 선형회귀를 사용하기 애매할때 사용된다.
🔻 numpy의 log 사용하기
y_train_log = np.log(y_train)# log값을 변환하고 했더니 오차가 오히려 더 커졌다 !
# 그러므로 우리의 데이터는 비선형이 아닌 선형에 가깝다.라는 결론이 나온다.
mean_squared_error(y_test, pred, squared=False)
'개발 > 머신러닝-딥러닝' 카테고리의 다른 글
| 2023.06.09 ML(머신러닝)의 로지스틱 회귀 (0) | 2023.06.13 |
|---|---|
| 2023.06.09 ML(머신러닝)의 의사결정나무(Decision Tree)모델 (0) | 2023.06.12 |
| 2023.06.08 ML(머신러닝)의 Kaggle(캐글),타이타닉 데이터셋 (0) | 2023.06.09 |
| 2023.06.08 ML(머신러닝)의 Iris(아이리스) (0) | 2023.06.08 |
| 2023.06.08 ML(머신러닝)의 Scikit-learn 모듈 (0) | 2023.06.08 |




댓글